
多元回归分析结果解读(一元回归分析)

以绵薄之力助力每一位创业者
用专业让品牌深入人心
电话:13877120151
这篇文章知识点为您总结归纳如下:15.多元回归分析、一元回归分析、多元回归分析预测
文章作者:数据与智能
数据与智能 本网站客服www.7our.com关注大数据与人工智能技术。由一批具备多年实战经验的技术极客参与运营管理,持续输出大数据、数据分析、推荐系统、机器学习、人工智能等方向的原创文章,每周至少输出7篇精品原创。同时,我们会关注和分享大数据与人工智能行业动态。欢迎关注。
来源 | Data Science from Scratch, Second Edition
作者 | Joel Grus
译者 | cloverErna
校对 | gongyouliu
编辑 | auroral-L
全文共4710字,预计阅读时间40分钟。
第十五章 多元回归分析
1. 模型
2. 最小二乘模型的进一步假设
3. 拟合模型
4. 解释模型
5. 拟合优度
6. 题外话:Bootstrap
7. 回归系数的标准误差
8. 正则化
9. 延伸学习
我不会盯着一个问题看,并往其中添加无用的变量。
——比尔· 帕塞尔斯
虽然副总对你的预测模型很满意,但是他认为你还可以做得更好。为此,你收集了额外的数据:对于每一个用户,你不仅了解他每天工作多少小时,同时还调查了他是否拥有博士学位。你希望通过这些补充资料来改进模型。
因此,你提出了一个带有更多自变量的线性模型:
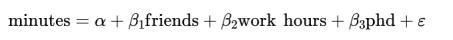
显然,用户是否拥有博士学位并非一个数值问题,但如同第 11 章所提到的,我们可以引入一个虚拟变量,当这个变量等于 1 的时候,表示用户拥有博士学位,反之则表示没有博士学位,这样就能像其他变量一样将其视为一个数值了。
1. 模型
回想一下,我们在第 14 章中所拟合的模型形式如下所示:
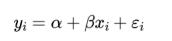
现在,如果每个输入 xi 不再是单个数字,而是一个由 k 个数字 xi 1,…, xi k 组成的向量,那么我们的多元回归模型则应该为:
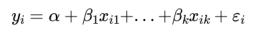
对于多元回归分析来说,参数向量通常称为 β。我们希望这个向量也包括一个常数项,为此,只要向我们的数据中添加一列即可:

同时:
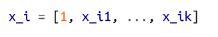
那么,我们的模型可以用下列函数实现:

在这种特殊情况下,我们的自变量x将是一个向量列表,每个向量都是这样的:

2. 最小二乘模型的进一步假设
对于我们的模型(以及我们的解决方案)来说,需要添加另外两个假设,才能够言之有理。第一个假设是 x 的各个列是线性无关的,即任何一列绝对不会是其他列的加权和。如果这个假设不成立,则无法估计 beta。为了了解极端的情形,我们可以想象数据中有一个额外的字段 num_acquaintances,并且对于每一个用户来说它都等于 num_friends。
那么,对于任何 beta,如果 num_friends 的系数增加了某个数值,而num_acquaintances 的系数同时减小相同数值的话,那么模型的预测就会保持不变。也就是说,我们根本就没有办法确定 num_friends 的系数。(通常来说,对于这个假设的违背情况一般不会这么明显。)
第二个重要的假设是 x 的各列与误差 ε 无关。如果这个假设不成立,对于 beta 的估计就会出现系统性的错误。
比如,在第 14 章中,我们建立的模型的预测结果为,用户每增加一个朋友,每天花在网站上的时间就会多出 0.90 分钟。
想象一下,还有下列情况:
? 工作时间越长的人在网站上花的时间越少。
? 朋友更多的人倾向于工作更长时间。
也就是说,假设“实际的”模型为:
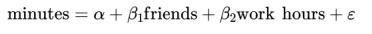
其中β2是负的,而工作时间和朋友则是正相关的。在这种情况下,当我们最小化单变量模型的误差时:
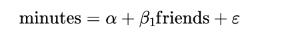
我们会低估 β1。
考虑一下,如果这个单变量模型已知 β1 的“实际”值,那么这时再用它来预测将会如何。(亦即,这个值来自令误差最小化的“实际”模型。)这时候,对工作时间比较长的用户来说,产生的预测值往往太小;对工作时间比较短的用户来说,产生的预测值往往又过大,这是因为 β2>0,但是我们“忘了”把它考虑进去。由于工作时间与朋友的数量是呈正相关的,这就意味着对于朋友数量较多的用户来说,模型给出的预测值往往太小;对于朋友数量较少的用户来说,模型给出的预测值往往太大。
这样做的结果是,我们可以通过降低 β1的估计值来减少(单变量模型)的误差,即误差最小化的 β1 是小于其“实际”值的。也就是说,在这种情况下,单变量的最小二乘解偏向于低估 β1。一般而言,当自变量具有与此类似的误差时,我们的最小二乘解给出的 β 是有偏估计。
3. 拟合模型
就像对简单线性模型所做的那样,我们这里也需要寻找一个能够最小化误差的平方和的beta。要想以手动方式找到一个精确的解可不是一件容易的事,因此,我们转而求助于梯度下降。下面我们首先创建一个待最小化的误差函数。误差函数几乎与我们在第14章中使用的完全相同,除了它不期望参数,而是需要一个任意长度的向量:

如果你熟悉微积分,可以通过下面的方式进行计算:

否则的话,就按照我说的来。
至此,我们就可以利用随机梯度下降法来寻找最优的 beta 了。让我们首先写出一个可以用于任何数据集的least_squares_fit函数:


然后,我们可以将其应用于我们的数据:
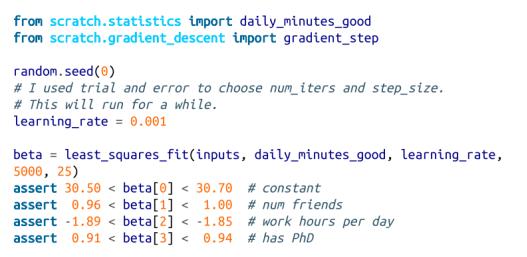
在实际实践中,你不会使用梯度下降来估计线性回归;你将使用超出本书范围的线性代数技术得到精确的系数。如果你这样做了,你就会得到以下公式:
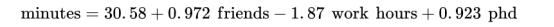
这和我们发现的很接近。
4. 解释模型
你应该把模型的系数看作在其他条件相同的情况下每个因素的影响力的大小。在其他条件相同的情况下,每增加一个朋友,每天花在网站上的时间就会多出一分钟。在其他条件相同的情况下,用户在工作日每多工作一个小时,每天花在网站上的时间就会减少两分钟。在其他条件相同的情况下,拥有博士学位的用户每天用在网站上的时间会多出一分钟。
但是,它没有(直接)反映变量之间的任何相互作用。较之于朋友较少的人而言,工作时间对朋友较多的人的影响很可能是不一样的,而这个模型并没有捕捉到这一点。要想处理这种情况,一种方法是引入一个新变量,即“朋友数量”与“工作时间”之积。这样实际上就使得“工作时间”的系数可以随着朋友数量的增加而增加(或减少)。
还有一种可能,就是朋友越多,花在网站上的时间就越多,但是达到一个上限之后,更多的朋友反而会导致花在网站上的时间变少。(或许是因为朋友太多了反而上网体验会很糟糕?)我们可以设法让模型捕获到这一点,方法是添加另一个变量,即朋友数量的平方。
一旦我们开始添加变量,我们就需要考虑它们的系数“问题”。对于添加的乘积、对数、二次幂以及更高次幂来说,其数量上是没有限制的。
5. 拟合优度
现在,我们再来看看 R 的平方值。

现在已经增加到0.68个:

但是不要忘了,只要向回归模型中添加新的变量就必然导致 R 的平方变大。归根结底,前面的简单回归模型只是这里的多元回归模型的特例而已,即“工作时间”和“博士”这两列的系数都等于 0。因此,最优的多元回归模型,其误差一定不会高于简单回归模型。
因此,对于多元回归分析而言,我们还要考察系数的标准误差,即衡量每个 βi 的估计值的可靠程度。
总的来说,回归模型通常能够很好地拟合我们的数据,但是,如果某些自变量是相关的(或不相关的),那么其系数就未必有多大的意义了。
对于这些误差,传统的度量方法通常都带有一个前提假设,即误差 εi 是独立的正态随机变量,其平均值为 0,标准偏差为σ(未知)。那样的话,我们(或者说我们的统计软件)就可以使用线性代数来确定每个系数的标准误差了。这个误差越大,说明模型的系数越不靠谱。令人遗憾的是,我们不打算从零开始介绍这类线性代数。
6. 题外话:Bootstrap
假设我们有一个含有 n 个数据点的样本,并且这些点是按照某种(我们不知道的)概率分布生成的:

在第 5 章中,我们曾经编写了一个计算观测数据中位数的函数,现在拿它来估算该分布本身的中位数。
但是,我们该如何了解这些估计值的可靠性呢?如果样品中所有的数据都非常接近 100,则实际的中位数很可能也非常接近 100。如果样本中一半左右的数据接近 0,而另一半则接近 200,那么我们就很难确信中位数到底接近多少。
如果我们能够不断获得新的样本,那么就可以计算出每个新样本的中位数,并观察这些中位数的分布情况。但是,一般这是不现实的。相反,我们可以利用 Bootstrap 来获得新的数据集,即选择 n 个数据点并用原来的数据将其替换,然后计算合成的数据集的中位数:


例如,考虑下列两个数据集:

如果你计算每个数据集的中位数,会发现它们都非常接近 100。然而,如果你考察下面的语句:

大部分情况下你看到的数字确实非常接近 100。然而,如果你考察下面的语句:

你会发现,不仅有许多数字接近 0,而且还有许多数字接近 200。
第一组中位数的 standard_deviation 接近 0,而第二组中位数的 standard_deviation 接近100:

(这种极端的情况通过人工检查数据很容易弄清楚,但一般情况下都不是真的。)
7. 回归系数的标准误差
我们可以采用同样的方法来估计回归系数的标准误差。我们可以对数据重复采用bootstrap_sample 样本,并根据这些样本估算 beta。如果某个自变量(如 num_friends)的系数在各个样本上变化不大,那么就可以确信我们的估计是比较严密的。如果这个系数随着样本的不同而起伏较大,那么我们就不能完全相信我们的估计。
唯一需要说明的是,采样前,我们需要把数据 X 和数据 Y 放到一起(用 zip),以确保对自变量和因变量一起进行采样。这就意味着 bootstrap_sample 将返回一个由(x_i, y_i)数据对组成的列表,因此我们需要将其重新组合成一个 x_sample 和一个 y_sample:


之后,我们就可以估算每个系数的标准偏差了:

(如果我们收集了100多个样本并使用5000多个迭代来估计每个测试版,我们可能会得到更好的估计,但我们没有一整天时间。)
我们可以使用它们来检验诸如“βi 等于 0 吗?”之类的假设。在满足 βi =0(以及与 εi 分布有关的其他假设)的条件下,则有:
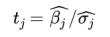
也就是说,这个统计量等于我们估算的 βj 除以估算的其标准误差,它符合具有“n-k 个自由度”的学生 t 分布(Student’s t-distribution)。
如果我们有一个 students_t_cdf 函数,那么就可以计算每个最小二乘系数的 p 值,从而指出实际的系数为 0 时观察到这个值的可能性有多大。令人遗憾的是,实际上我们没有这样的函数。(虽然我们不想从头做起。)
然而,随着自由度变大,t 分布越接近标准正态分布。在这种情况下,即 n 比 k 大得多的情况下,我们便可以使用 normal_cdf 了,并且我们觉得它效果还不错:

(在其他情况下,我们很可能会使用一个知道如何计算 t 分布和精确的标准误差的统计
软件。)
虽然大多数系数的 p 值都非常小(但非 0 值),但是“博士学位”的系数与零没有“显著”区别,也就是说“博士学位”的系数很可能是随机的,无意义的。
在对回归分析要求更加精细的情形下,你可能需要对数据的各种假设进行更加细致的测试,比如“至少有一个 βj 是非 0 值”,或者“β1 等于 β2 且 β3 等于 β4”等,以便进行 F 测试,但是这些内容已经超出了本书的讨论范围。
8. 正则化
在实践中,线性回归经常需要处理具有很多变量的数据集,这时就需要用到另外两个技巧。首先,涉及的变量越多,模型越容易对训练集产生过拟合现象。其次,非零系数越多,越难以搞清楚它们的意义。如果我们的目标是解释某些现象,一个只考虑三方面因素的稀疏型模型通常要比涉及数百个因素的模型要更好一些。
正则化是指给误差项添加一个惩罚项,并且该惩罚项会随着 beta 的增大而增大。然后,我们开始设法将误差项和惩罚项的组合值最小化。因此,惩罚项权重越大,就越能防止系数过大。
例如,在岭回归(ridge regression)中,我们添加了一个与 beta_i 的平方之和成正比的惩罚项。(当然,我们一般不会惩罚 beta_0,因为它是个常数项。)


然后,我们可以用通常的方式将其插入到梯度下降中:

然后我们只需要修改least_squares_fit函数来使用sqerror_ridge_gradient而不是sqerror_gradient。(我不会在这里重复该代码。)
如果alpha设置为0,根本没有惩罚,我们得到与以前相同的结果:

随着 alpha 的增大,拟合优度会变差,但是 beta 会变小:

特别地,随着惩罚项的增大,“博士学位”的系数会变成 0,这与我们之前的结果是一致的,即它与 0 没有显著区别。
注意
在利用这个方法之前,通常需要调整数据的规模。因为即使是同一个模型,如果将几年数据一下变为几百年的数据,那么它的最小二乘法系数就会增加上百倍,那样得到的惩罚肯定也会骤增。
还有一个方法是 lasso 回归,它用的惩罚方式如下所示:

总的说来,岭回归的惩罚项会缩小系数,但是,lasso 的惩罚项却趋向于迫使系数变为 0值,这使得它更适于学习稀疏模型。令人遗憾的是,它不适用于梯度下降法,这意味着我们将无法从头开始解决这个问题。
9. 延伸学习
? 回归分析具有深厚而广阔的理论背景。要想了解这些背景理论,你需要阅读相应的教科
书,至少也得阅读大量的维基百科文章。
? scikit-learn 的 linear_model 模块提供了一个 LinearRegression 模型,它跟我们的模型颇为相近。此外,它还提供了Ridge 回归和 Lasso 回归,以及其他类型的正则化算法。
? 另一个相关的 Python 模块是 Statsmodels(它也包含了线性回归模型及许多其他内容。
服务价目表
(本站部分图文来自网络,如有侵权核实后立即删除。微信号:tigerok )