
每天一点数据分析——回归分析

以绵薄之力助力每一位创业者
用专业让品牌深入人心
电话:13877120151
文章作者:懂码杂记
了解相关关系后,现在来学习第二种关系——回归函数关系。通过数据间的相关性,可以进一步构建回归函数关系,即回归模型,预测数据未来的发展趋势。
回归是研究自变量与因变量之间关系形式的分析方法,它主要是通过建立因变量Y与影响它的自变量X之间的回归模型,来预测因变量Y的发展变量。例如,销售额对推广费用有着依存关系,通过对这一依存关系的分析,在已确定下一期推广费用的条件下,可以预测将实现的销售额。
相关分析和回归分析的联系与区别
相关分析与回归分析的联系是:
均为研究、测量两个或两个以上变量之间关系的方法。在实际工作中,一般先进行相关分析,计算相关系数,然后拟合回归模型,进行显著性检验,最后用回归模型推算或预测。
相关分析与回归分析的区别是:
相关分析研究的都是随机变量,并且部分自变量与因变量,回归分析研究的变量有自变量与因变量之分,并且自变量是确定的普通变量,因变量是随机变量;
相关分析主要描述两个变量之间线性关系的密切程度,回归分析不仅可以揭示变量X对变量Y的影响大小,还可以由回归模型进行预测。
回归分析模型主要包括线性回归及非线性回归。线性回归又分为简单线性回归与多重线性回归,而对于非线性回归,我们通常通过对数转化等方式,将其转化为线性回归的形式,所以接下来将重点学习线性回归。线性回归分析主要有五个步骤:

简单线性回归
简单线性回归也称为一元线性回归,也就是回归模型只含一个自变量,否则称为多重线性回归。简单线性回归模型为:
Y = a + bX + ε
Y——因变量
X——自变量
a——常数项,是回归直线在纵坐标上的截距
b——回归系数,是回归直线的斜率
ε——随机误差,即随机因素对因变量所产生的影响
结合Excel回归分析工具,以“企业季度数据”为例,先不考虑其他费用因素,只考虑推广费用对销售额的影响,如果确定了2012年第3季度推广费用预算,通过给出的数据,如何预测2012年第3季度销售额呢?
一、绘制散点图
散点图是一种比较直观地描述变量之间相互关系的图形。一般在做线性回归之前,需要先用散点图查看数据之间是否具有线性分布特征,只有当数据具有线性分布特征时,才采用线性回归分析方法。
1、【插入】选项卡中,选择【散点图】,选择数据源,进行相关设置:
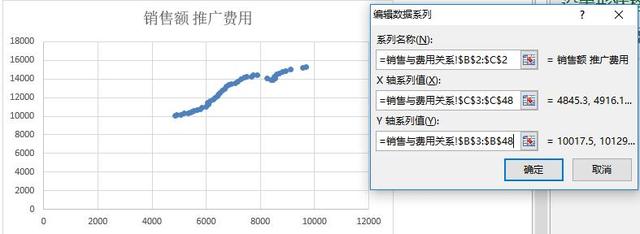
2、右击散点图,添加趋势线,并显示拟合直线方程和R平方值;
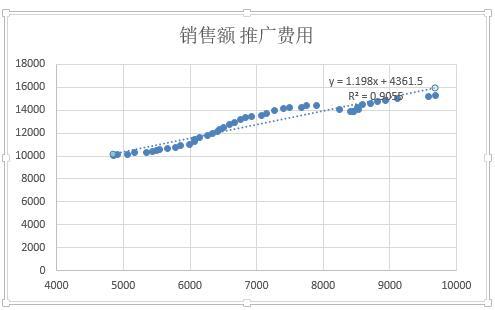
这里只是通过绘图的方式建立回归分析模型的一个简单做法,之后还要进一步使用多个统计指标来检验,如回归模型的拟合优度检验(R^2)、回归模型的显著性检验(F检验)、回归系数的显著性检验(t检验)等综合评估回归模型的优劣,这时就需要使用到Excel分析工具库中的“回归”分析工具来实现了。
3、在【数据分析工具】中选择“回归”分析工具进行相关设置:
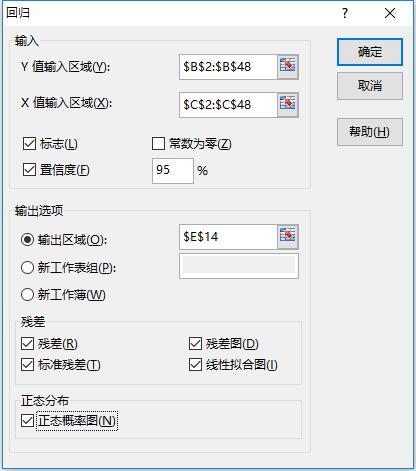
其中,残差是指观测值与预测值(拟合值)之间的差,也称剩余值;标准残差是指(残差-残差的均值)/残差的标准差;残差图是以回归模型的自变量为横坐标,以残差为纵坐标绘制的散点图。若绘制的点在以0为横坐标的直线上下随机分布,则表示拟合结果合理,否则需要重新建模;线性拟合图是以回归模型的自变量为横坐标,以因变量及预测值为纵坐标绘制的散点图;正态概率图是以因变量的百分位排名为横坐标,以因变量作为纵坐标绘制的散点图。
最后生成结果如下:
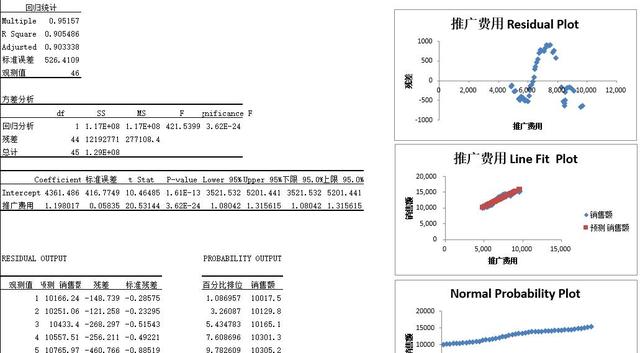
通过“回归”分析工具生成了回归统计表、方差分析表、回归系数表,而这三张表就分别用于回归模型的拟合优度检验(R^2)、回归模型的显著性检验(F检验)、回归系数的显著性检验(t检验)。
回归统计表
回归统计表用于衡量因变量Y与自变量X之间相关程度的大小,以及检验样本数据点聚集在回归直线周围的密集程度,从而评价回归模型对样本数据的代表程度,即回归模型的拟合效果,主要包含以下5个部分。
Multiple R:因变量Y与自变量X之间的相关系数绝对值。本例中R=0.9516,销售额与推广费用成高度正相关;
R Square:判定系数R^2(也称拟合优度或决定系数),即相关系数R的平方,R^2越接近1,表示回归模型拟合效果越好。本例中R^2=0.9055,回归模型拟合效果好;
Adjusted R Square:调整判定系数Adjusted R^2,仅用于多重线性回归时才有意义,它用于衡量其他自变量后模型的拟合程度。
标准误差:其实应当是剩余标准差(Std. Error of the Estimate),在对多个回归模型比较拟合程度时,通常会比较剩余标准差,此值越小,说明拟合程度越好。这里的标准误差为526.41。
观测值:用于估计回归模型的数据个数(n),这里的n = 46。
方差分析表
方差分析表的主要作用是通过F检验来判断回归模型的回归效果,即检验因变量与所有自变量之间的线性关系是否显著,用线性模型来描述它们之间的关系否巧当。表中主要有Df(自由度),SS(误差平方和)、MS(均方差)、F(F统计量)、Significance F(P值)五大指标,通常我们只需要关注F、Significance F两个指标,其中主要参考Significance F,因为计算出F统计量,还需要查找F分布临界值表,并与之进行表叫才能得出结果,而P值可直接与显著性水平α比较得出结果。
F:F统计量,用于衡量变量间线性关系是否显著,这里的F = 421.54;
Significance F:是在显著性水平α(常用取值0.01或0.05)下的F的临界值,也就是统计学中常说的P值。一般我们以此来衡量检验结果是否具有显著性,如果P值>0.05,则结果不具有显著的统计学意义;如果0.01<P值<=0.05,则结果具有显著的统计学意义;如果P值<=0.01,则结果具有及其显著的统计学意义。
回归系数表
回归系数表主要用于回归模型的描述和回归系数的显著性检验。回归系数的显著性检验,即研究回归模型中的每个自变量与因变量之间是否存在显著的线性关系,也就是研究自变量能否有效地解释因变量的线性变化,它们能否保留在线性回归模型中。
回归系数表中,第一列中的Intercept、推广费用,分别为回归模型中的a(截距)、b(斜率),对于大多数回归分析来讲,关注b要比a重要;第二列是a和b的值,据此可以写出回归模型;第四、五列分别是回归系数t检验和相应的P值,P值on个样与显著性水平α进行比较,最后一列是给出的a和b的95%的置信区间的上下限。
我们最后得到的销售额和推广费用的简单线性回归模型为Y = 4361.4864 + 1.1980X,其中判定系数R^2=0.9055,回归模型拟合效果较好。回归模型的F检验与回归系数的t检验相应的P值都远小于0.01,具有显著线性关系。综合来说,回归模型拟合较好。
多重线性回归
多重线性回归模型是指包含一个因变量和多个自变量的回归模型,而多元线性回归是指包含两个或两个以上因变量的回归模型。所以多重线性回归模型为:
Y = a + b1X1 + b2X2 + ...... + bnXn + ε
Y——因变量
Xn——第n个自变量
a——常数项,是回归直线在纵坐标上的截距
bn——第n个偏回归系数
ε——随机误差,即随机因素对因变量所产生的影响
依然可以采用Excel分析工具库的“回归”分析工具来实现,之前在进行回归设置的时候,“X值输入区域”只选择了推广费用,而多重线性回归需要同时选择推广费用和其他费用,这是和简单线性回归设置的唯一区别。最后生成结果如下:

多重线性回归中,回归模型拟合优度的检验应该采用调整判定系数Adjusted R^2,最终得到的销售额与推广费用、其他费用的多重线性回归模型为Y = 4943.9764 + 1.8844X1 - 3.7513X2,其中调整判定系数Adjusted R^2 = 0.94,回归模型拟合效果较好,回归模型的F检验与回归系数的t检验相应的P值都远小于0.01,具有显著性线性关系,综合来说,回归模型拟合较好。
服务价目表
(本站部分图文来自网络,如有侵权核实后立即删除。微信号:tigerok )